Continuation Passing Style
By Brandon Wu, June 2020. Revised March 2022
We have seen how we can write functions that are tail recursive, in that they only make recursive calls as tail calls, where the recursive calls is the last thing that the function does (i.e. there is no deferred work). This commonly was realized by implementing the tail-recursive function with an accumulator, which simply stored the intermediate values that were computed. In this section, we will explore an concept known as continuation-passing style, which sees the use of functions as accumulators, which lets us use more explicit logic when encoding the control flow of our programs, as well as the intermediate results of our computations.
Continuation Passing Style: The Idea
Consider the computation of (2 + 3) * 4.
Clearly, there is an ordering to how we should evaluate this. We should sum 2 and 3 first, then take the result of that and multiply it by 4. There is kind of a catch here, that is quickly glossed over by our human brains - we refer to "the result of that" rather casually. We haven't explicitly named it, but we nonetheless make an appeal to intuition to get our point across.
How else might we represent this computation? Well, we could use lambda expressions, and then use the power of function application to compute the result. Then, we might obtain that this is akin to evaluating (fn res => res * 4) (2 + 3). This would be a more direct translation of the idea of "add 2 and 3, then pass the result of that to 4". We note that, in the process, we have explicitly made clear what we mean by "the result of that" - it is now bound to a name, that being res.
We can take this one step further. If we think about it a bit more, we might want to consider starting at a "single" value, so that we don't have to consider the operation of 2 + 3 as one step. Then, we might instead write "take 2, add the previous result to 3, and then multiply the previous result by 4". Clearly, we have now made it deliberate that we are passing around a single value that we are performing operations on at each step. How would we write this as a lambda expression, however?
We might write (fn res => (fn res2 => res2 * 4) (res + 3)) 2 to encode the previous instructions. This essentially makes res the first "previous result", and then the result of 2 + 3 is res2, the second "previous result". Make sure you understand what is happening here - we are binding 2 to the identifier res, then binding the result of res + 3 to the identifier res2.
However, it is still on us to provide the value of 2. We to somehow encode the notion of the computation of (2 + 3) * 4, not necessarily evaluating the expression ourselves. We know that placing an expression within the confines of a lambda expression will "freeze" the computation, causing it to only resume once the lambda expression is given an input, so what we can do is simply do the same with a trivial input. Our trivial input here will be (), or unit, since we always have access to it, and there is only one value of type unit.
So somehow, we can encode the idea of this expression with (fn () => (fn res => (fn res2 => res2 * 4) (res + 3)) 2). Seen in this way, we have somehow encoded the desired expression not by actually executing it, but forming some large function a priori that essentially does the same thing. We thus form a correspondence between evaluating an expression by carrying out each step in real time and by writing out the steps to be done at a later time. We hope to show that two are really equivalent - this will be important to understand for later.
Continuation Passing Style: A Case Study
We will now discuss continuation passing style more explicitly.
It is hopefully clear that the previous example of (fn () => (fn res => (fn res2 => res2 * 4) (res + 3)) 2) encodes, in some form, the idea of the computation of the expression (2 + 3) * 4. Somewhat key, however, is that computation does not execute until we actually feed a unit to it. It is important to note the distinction between doing something and writing the instructions to do something. A continuation can be thought of as a blueprint, or a contingency plan. We will expand more on what we mean by this shortly, but a continuation essentially represents what instructions need to be executed. This is a very powerful idea, because programs can continuously alter continuations by adding more instructions or even executing different continuations in order to determine what computations ultimately need to be executed.
We will first consider a simple example before going into the definition.
(* factCPS : int -> (int -> 'a) -> 'a *)
(* REQUIRES: true *)
(* ENSURES: factCPS n k ~= k (n!) *)
fun factCPS 0 k = k 1
| factCPS n k = factCPS (n-1) (fn res => k (n * res))
Here, factCPS takes in two arguments - one is the counter for the factorial function (as normal), and the other is the continuation. In this case, the continuation is a function from int -> 'a. The idea here is that the continuation should represent what work is left to do. It is left polymorphic, however, in order to give the user control over what they want the function to do. In order to compute the factorial of n directly, one could just evaluate factCPS n Fn.id, however we grant more versatility to the user in that they are not just constrained to computing the factorial. If one wanted a textual representation of the factorial of n, they could evaluate factCPS n Int.toString, for instance. This way, we get additional versatility out of our implementation.
We will now consider a trace of factCPS 3 Int.toString to fully understand the mechanism by which it works.

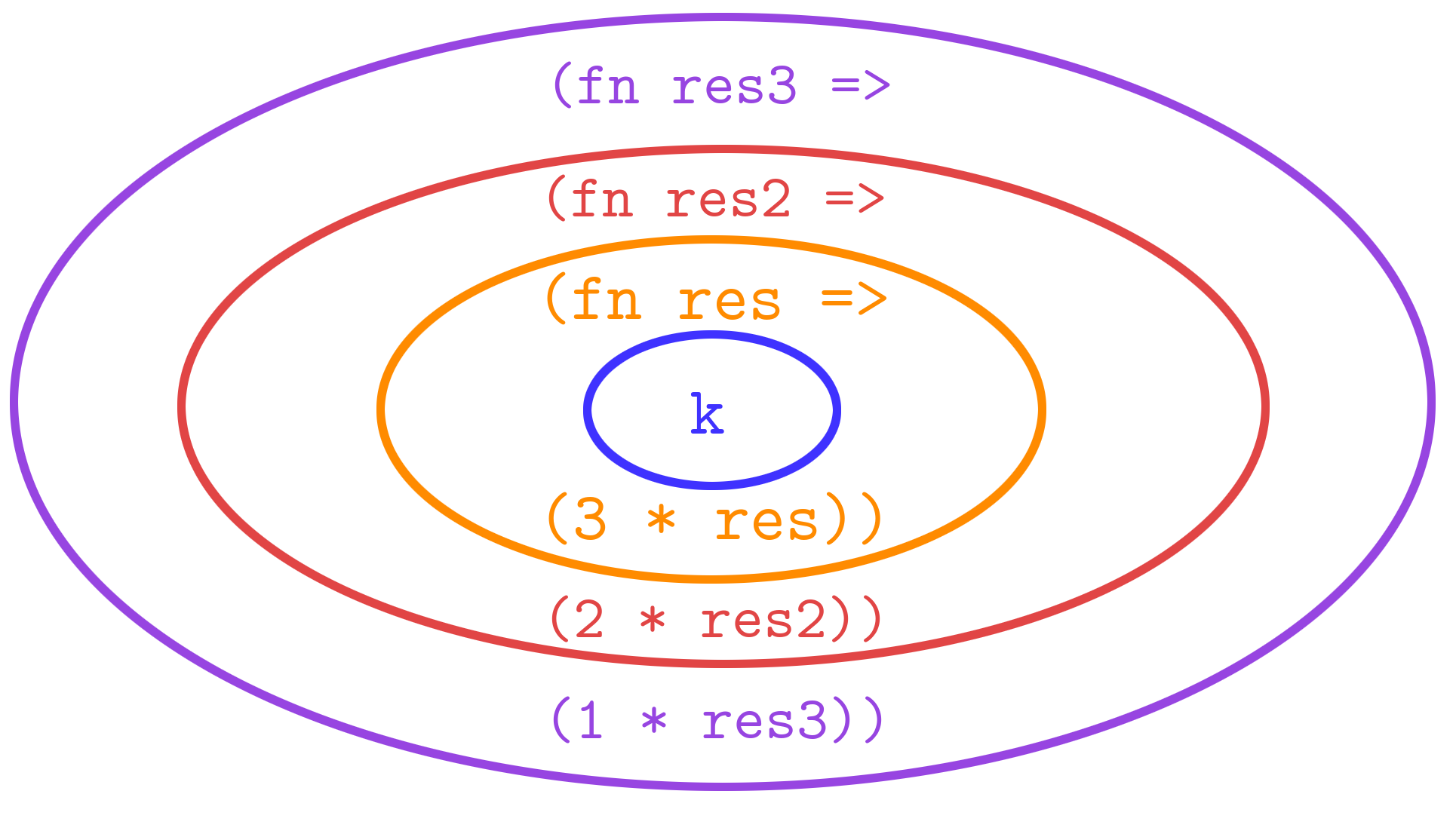
factCPS 3 Int.toStringAs we can see, this code trace does correctly result in Int.toString 6, which is our desired result. Of particular interest to our analysis is the continuation of the function, which seems to grow with every line through factCPS's recursion, until ultimately being reduced down step-wise until it yields our final result.
The colors in the image denote the difference between the current value of k and the new, constructed k. For instance, k is originally Int.toString (which is the blue-colored text), however it is eventually wrapped in (fn res => ... (3 * res)), which is the RHS of the call to factCPS 3 Int.toString. Thus, the "inner" k in the third line is in orange, to signify that it is in fact the same as the entire continuation from the previous line (also in orange), which is the "previous" k. Seen in this way, all that each recursive call seems to be doing is appending a layer to the continuation, while the inside remains the same.
NOTE: The definition of factCPS says that the input to each lambda expression should be named res. In order to make understanding clearer and avoid namespace collisions, we have opted to name it res, res2, and res3, on each recursive call to factCPS. Note that this renaming does not affect the evaluation of factCPS 3 Int.toString and does keep it exactly equivalent to how it is actually evaluated.1
So hopefully now we are convinced of factCPS's correctness.2 What might not be evident, however, is why.
Recall our previous metaphor with regards to writing down instructions. It is hopefully not too difficult to see that this large lambda expression that we are constructing is akin to writing down instructions - we specify the operations that should occur when it is ultimately "collapsed" (by being given an input value), but nothing actually occurs until then. It merely encodes that information in the meantime. The next diagram will attempt to more specifically show this relationship between the "instructions" and how it arises from the definition of factCPS:

factCPS and the "instructions" that it writes down.The middle of this image is supposed to denote the "instructions" that you might write if you were to codify the algorithm to determine the factorial of . Note that these instructions are actually read from bottom to top - thus, we start with 1 and then work out way up multiplying until we reach , which presumably should give us the actual factorial.
Now consider if we were at some arbitrary point of execution of the expression factCPS n initK, for some arbitrary initK : int -> 'a. That is, suppose that factCPS n initK has reduced down to factCPS i k', for some other k (which is the result of modifying the continuation throughout the recursive calls of factCPS until now. Then, we should see that the form of k should look something like (fn res => (fn res2 => ... (fn resn => initK (n * resn)) ... ((i + 2) * res)) ((i + 1) * res)). That is, it exactly captures the idea of the instructions in orange - it covers the multiplication of all of the terms from to .
What is the action of the recursive call at factCPS i k? Well, clearly it should reduce to factCPS (i-1) (fn res => k (i * res)) - that is, it wraps k in the lambda expression (fn res => k (i * res)), which is just the "instruction" to multiply the result by i, which exactly corresponds to the instruction in blue.
How do we compute the rest of the factorial function? Everything seems correct so far, but that is all that we will have in our accumulation of k. The rest of the instructions are exactly corresponding to the recursive call - to factCPS i itself. factCPS i, as the recursive call, will continue to go and compute the factorial all the way down to 0. Thus, even though we have not written them down yet, we can use the "recursive leap of faith" to assume that factCPS i k will behave properly, and write down the instructions for multiplying i-1 through 1 properly, which will result in the final, correct result.
NOTE: An equivalent, but also very important way to view CPS functions is that recursive calls pass their result to their continuation. For instance, as we have defined, factCPS n k should be extensionally equivalent to k (fact n), or in other words, factCPS n k will be the same as passing the actual factorial of n to k. This means that when we are writing our function, we can make that assumption - factCPS (n-1) (fn res => k (n * res)) should pass the result of to (fn res => k (n * res)). This is equivalent to, in our "instructions" analogy, saying that factCPS i k should faithfully execute all the instructions of multiplying from 1 to i - that is, factCPS i k should pass the result of to k.
So now, we can sort of inductively see how factCPS writes down the entire page of instructions, which should mean that it is correct when we execute it. This is not an inductive proof in itself, but this should give the intuition for why it does work.
An additional way to think about CPS functions is that they behave similarly to a stack. This is because, as we have seen, we are continuously wrapping lambda expressions with other lambda expressions - we can only "pop" off a lambda expression by evaluating it with an argument, or "push" on more instructions by wrapping our continuation in more lambda expressions. We cannot access the ones inside. As such, we could visualize the evaluation of factCPS 3 k as the following diagram:

factCPS 3 k.We would build this stack up from the bottom by first putting our k on (as our "original" k), then wrapping it in more lambda expressions as we go along the recursive calls (so, for instance, the orange brick is added by factCPS 3 k', and the red brick is added by factCPS 2 k'', for their own respective continuations k' and k''). Then, once we are at the end, our "instruction stack" looks like the one currently pictured. At that point, we have nothing left to do but execute the stack of instructions with an initial value of 1, which will cause the bricks to start being popped off one by one, and then ultimately result in the value of 6 being applied to k.
Another, equivalent way to view continuations is as donuts.
factCPS 3 k (colorized, 2020).As you can see, we cannot access the inner layers of the CPS Donut without first biting through the outer layers (corresponding to our evaluation of the outer layers first). One can only imagine what it would taste like in real life.
NOTE: It is not important to be able to draw these examples, or parrot them verbatim. They are merely here to try and provide some intuition as to what is happening with CPS. It is very important to be able to understand why it is that CPS functions work, which may be rather daunting and hard-to-grasp at first.
Continuation Passing Style: The Definition
We are now ready to attempt a definition of continuation passing style.
[Continuation] A continuation is a function that specifies what is supposed to be done with the result of a computation.
[Continuation Passing Style] A function is said to be written in continuation passing style if it satisfies the following conditions:
It takes in and uses continuation(s).
It calls functions with continuations (including itself) as tail calls.
It can only call its continuations in tail calls.
The key characteristic of CPS functions is that they are generally written with the goal of passing their results to their continuations. These continuations specify what computations should occur next.
First, take a moment to assure yourself that the implementation of factCPS that we have so deeply studied is, in fact, in continuation passing style.3
fun factCPS 0 k = k 1
| factCPS n k = factCPS (n-1) (fn res => k (n * res))
As we have seen, clearly k is factCPS's continuation, and it does call it in tail calls (as well as itself). This seems consistent with our definition.
An important corollary of this definition is that a CPS function cannot case on a recursive call to itself. So, for instance, making a recursive call to a CPS function to see if it succeeds, then taking some action based on that premise is illegal. You may not fully understand what that means at the present, but we will explore this idea more in the future.
A somewhat interesting note is that every direct-style (which is how we will term the kinds of functions that we have written until now) function admits a continuation passing style implementation. This means that continuation passing style is nothing arcane, but it is merely a different way of viewing computation. Functions written in continuation passing style can have significant performance benefits when compared to their direct style counterparts, so there are reasons to use continuation passing style other than just for the sake of it.
Continuation Passing Style: A Case Study v2.0
We will now explore an example of a CPS function that makes use of some concept of limited backtracking, or checkpointing. Somewhat key to this example is that it writes down not just one instruction at each recursive call, but multiple.
fun treeSumCPS Empty k = k 0
| treeSumCPS (Node (L, x, R)) k =
treeSumCPS L (fn leftSum => treeSumCPS R (fn rightSum => k (leftSum + x + rightSum))
This function computes the sum of the elements in an int tree. The recursive case has a slightly more intimidating-looking continuation, however we can view it as simply a case of the continuation being wrapped twice.
Consider how we would normally want to approach this problem. In a typical treeSum, we might compute both the left and right sums, and then simply add the results to x. This suffices, and follows rather intuitively, but in CPS we must make our control flow explicit. In this manner, we must be very specific about what we should do and in which order. To that end, we fix a direction to visit first (in this case, left, though it does not matter), and then compute the sum of that direction, with the promise that we will eventually use the result of the left side to compute the final result.
To visualize what is happening, consider the following tree.
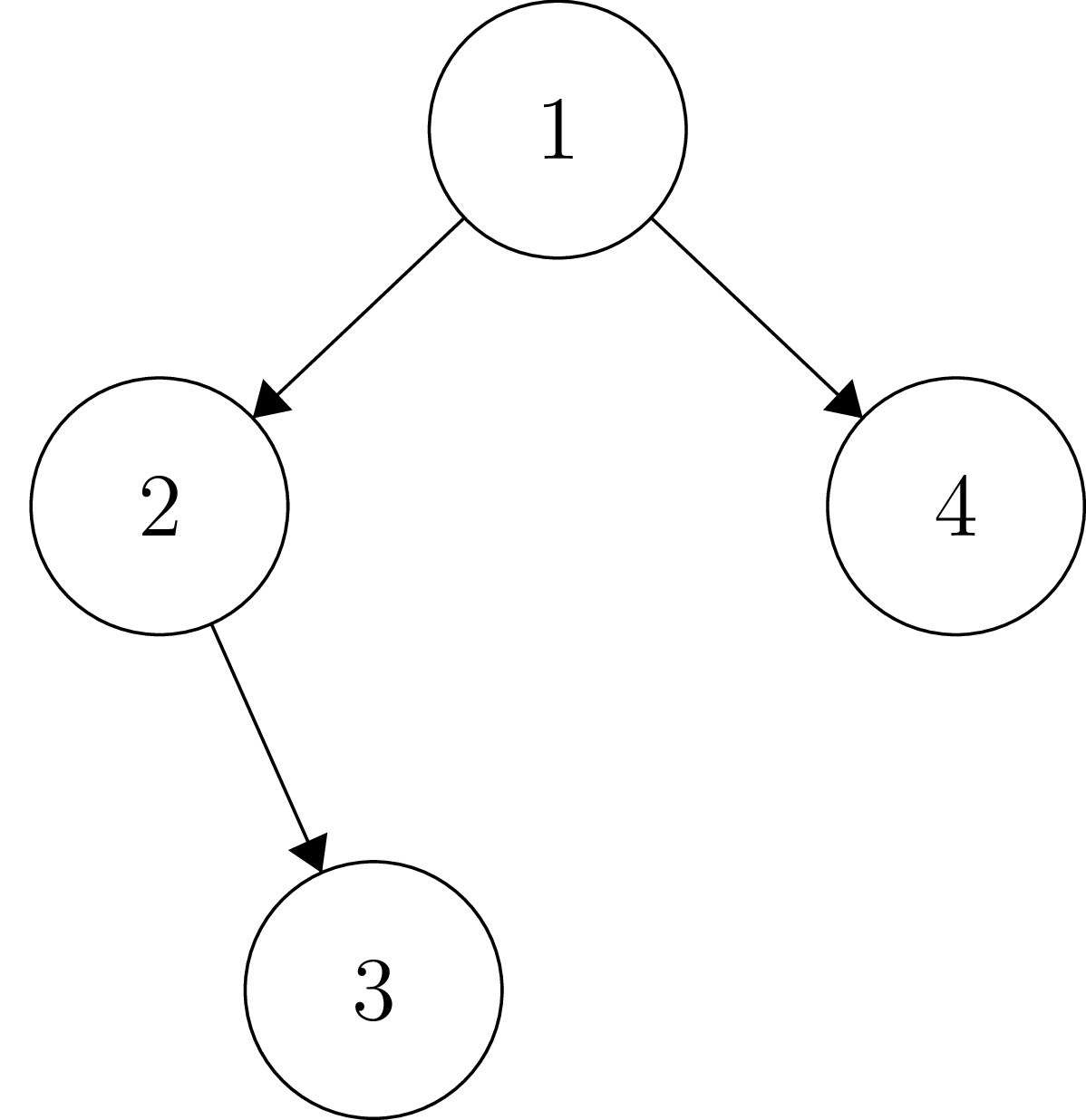
We will run through a mock simulation of the evaluation of treeSumCPS T k, where T is the tree pictured, and k is some arbitrary continuation. First, note that we will take the convention that "Tn" for some number n will denote the subtree rooted at the vertex n, and "Sn" will denote the sum of that subtree.
Firstly, we know that from treeSumCPS T k we should obtain treeSumCPS T2 (fn S2 => treeSumCPS T4 (fn S4 => k (S2 + 1 + S4)).
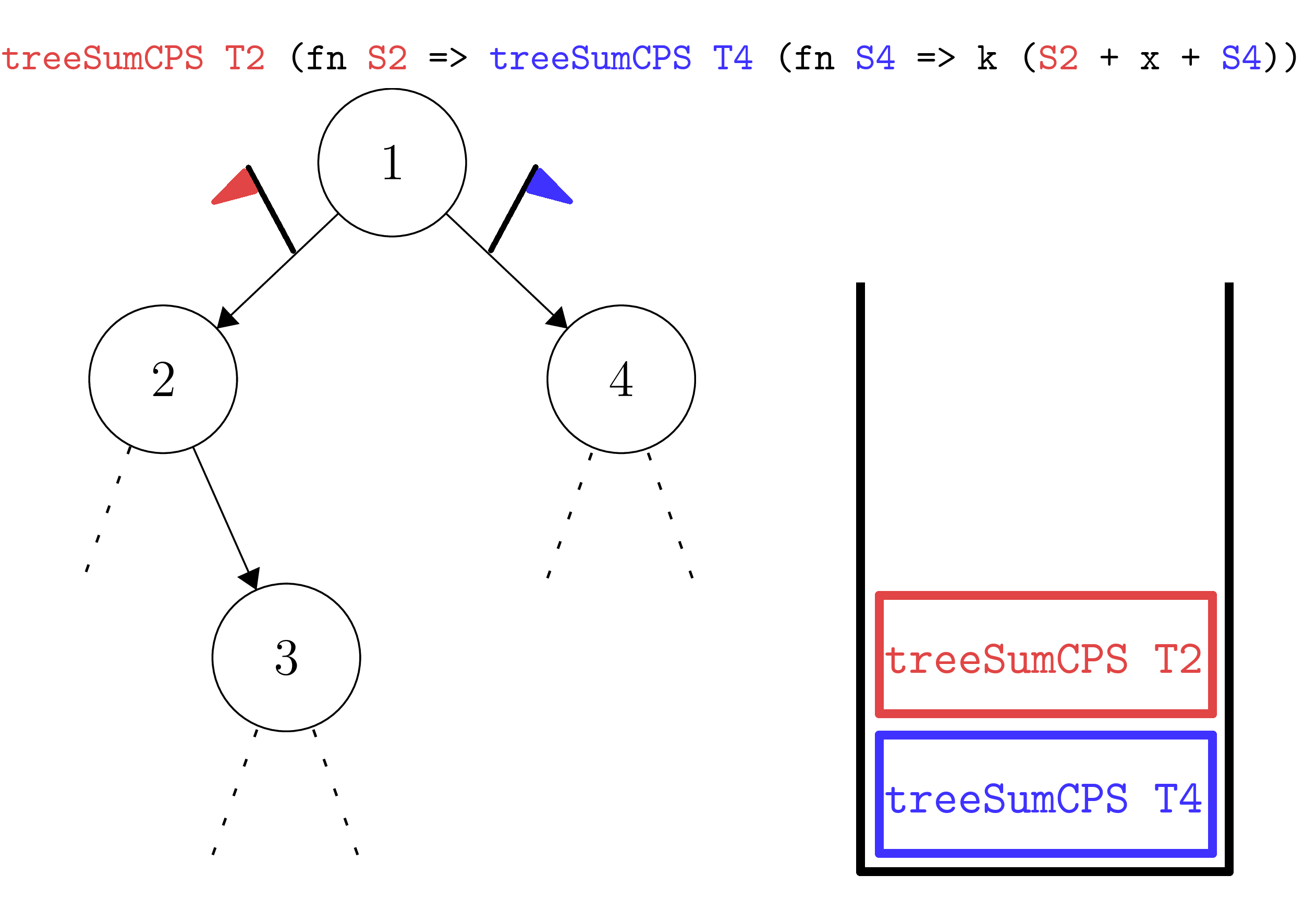
We can think of the individual calls to treeSumCPS on T2 and T4 as leaving "flags" on each arm of the edges coming from vertex 1 - denoting which node that we should visit next. Clearly, we visit T2 first, so the red brick corresponding to T2 is on top.
Our next move is to pop it off first, which will cause our expression to now have three bricks - two corresponding to the children of T2, and one corresponding to T4. We can visualize the next phase as the following:
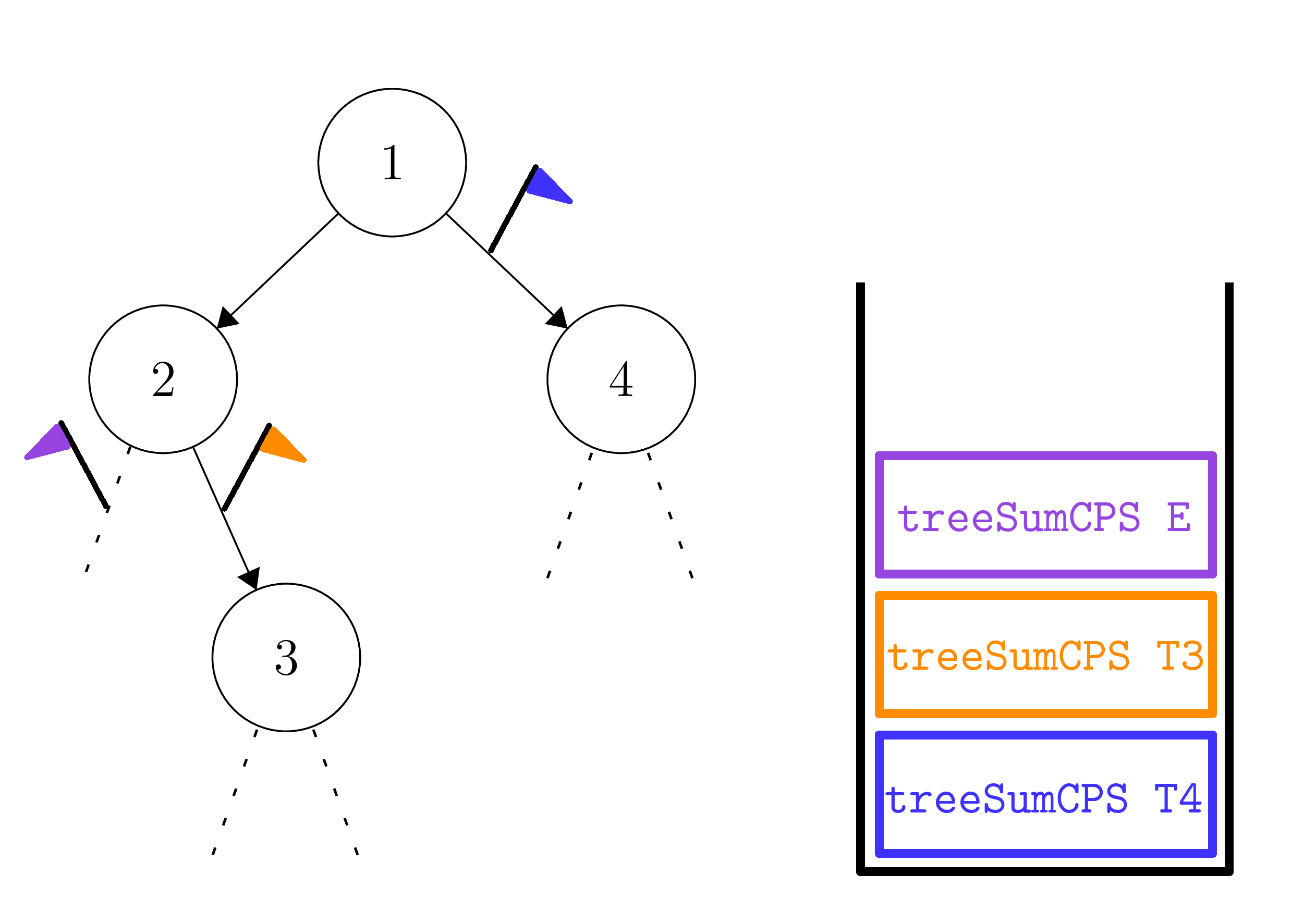
where the brick labelled treeSumCPS E corresponds to the empty child of T2. Note that we have retained the blue flag at T4 and left its brick alone, since for all intents and purposes we have not yet "touched" it - we have not evaluated our stack to that point. Note that due to corresponding to the Empty case, the purple brick will not add any new bricks, but merely defer to the next brick on the stack - the orange brick. Thus, the next step looks like the following:

In this step, the green and light blue bricks again correspond to empty trees, so they simply dissolve without generating more instructions. As such, we reduce to the following diagram:

We see in this step that, as the figure caption says, we have returned to the right hand side after finishing all evaluation on the left hand side of the tree. Thus, our construction was correct - we placed the blue brick onto the stack at the very beginning, then proceeded to forget about it until now. This works in our favor, however, as we only return to it once we have finished with everything on the left. One more step of evaluation yields:

Thus, all we have left are empty bricks, so we are very close to termination.
This demonstration was far from a rigorous treatment, and also omitted any mention of the actual value being passed into each continuation - this can be inductively assumed to be the proper sum at any given brick. We invite the reader to conduct any detailed analysis on their own, similarly to the treatment of factCPS, in order to truly grasp how the different subtree sums are computed and passed around.
The main point in this example, however, was to demonstrate how even a slightly more complicated function can result in elegant, powerful control-flow behavior. By simply wrapping our continuation twice, we ensured that we could set up a "checkpointing" system, where we could set "flags" to jump back to once finishing a certain computation. This is an important idea to cognize with continuation passing style.
In the next example, we will explore how we can set up more complicated arrangements of control flow through usage of two continuations.
Continuation Passing Style: A Case Study in Success and Failure
Duality seems to permeate computational problems. When trying to write programs, we often come to cases where we need to make a choice between two extremes - on or off, keep or don't, left or right, 1 or 0. With the capacity to make choices, however, comes the possibility of making the wrong choice. In such a case, we might want the ability to remember the choice we made, and take the other one, or backtrack.
[Backtracking] Backtracking is a strategy employed by algorithms when trying to find all the possible "options" or "possibilities", so as to locate the "best" solution, or alternatively just one feasible solution. Problems that admit backtracking solutions include the N-queens puzzle, constraint satisfaction problems, and Sudoku.
At first, backtracking might seem like it is akin to what was done in the previous example, with our idea of "checkpointing", except that we never really "reset" our state. When we set checkpoints to go back to in the treeSumCPS example, we always did so while retaining the sum of the left side, so we never lost information. In a backtracking problem, we may need to throw away everything that we've done in the meantime and go to a different solution entirely.
In this example, we will analyze a classic optimization problem, and how it admits a CPS solution.
[Knapsack Problem - Decision Version] The knapsack problem is a resource allocation problem which traditionally concerns a person with a knapsack that can only contain a certain total weight of items. The person has to choose between a collection of items (all of differing weight and value) so as to maximize the amount of value collected, while being below the maximum weight limit of the knapsack. Note that items can be taken more than once.
In this chapter, we will be concerned specifically with the decision problem version of the knapsack problem, which, instead of asking for a maximizing assignment, instead asks if there exists an assignment that can achieve a certain threshold of value.
We will now write a continuation passing style function that solves the knapsack problem.
type weight = int
type value = int
(* knapsackCPS :
* (value * weight) list ->
* value ->
* weight ->
* ((value * weight) list -> 'a) ->
* (unit -> 'a) ->
* 'a
* REQUIRES: The weights and values of the elements in L are strictly positive.
* ENSURES: knapsackCPS L minVal maxWeight sc fc ~= sc L' for some L' that only
* contains elements of L, such that the total value of L' >= minVal and the
* total weight of L' <= maxWeight, if such an L' exists. If no such L' exists,
* then it should be equivalent to fc ().
*)
fun knapsackCPS
(L : (value * weight) list)
(minVal : value)
(maxWeight : weight)
(sc : (value * weight) list -> 'a)
(fc : unit -> 'a)
: 'a =
case L of
[] => if minVal <= 0 andalso maxWeight >= 0 then sc []
else fc ()
| (v, w)::xs => if maxWeight < 0 then fc ()
else
knapsackCPS ((v, w)::xs) (minVal - v) (maxWeight - w)
(fn L' => sc ((v, w)::L')) (fn () => knapsackCPS xs minVal maxWeight sc fc)
We see that knapsackCPS takes in a list of items, each represented as a value * weight tuple, where value and weight are both really just aliases for int. It also takes in a minimum threshold for the knapsack's value, minVal, and a maximum weight of items to be taken maxWeight. Of particular interest, however, are the parameters sc and fc - denoting what we call the success and failure continuations. The goal of our function is to ultimately find a list L' that contains elements that are also in L (with duplicates allowed). This corresponds to choosing how many of each item in the allowed collection to pick.
If such a list exists, then we should return sc L'. Otherwise, if there is no such list, we should return fc ().
Rather immediately, this should seem as a kind of different problem. There isn't really a better algorithm than brute forcing possibilities, but if we try a possibility and it turns out to be wrong, we want to have the option to be able to backtrack and try something else entirely. We will demonstrate how this is realized in the algorithm in the next part.
case L of
[] => if minVal <= 0 andalso maxWeight >= 0 then sc []
else fc ()
For the base case, however, we know that if we are given no items whatsoever, then we cannot place anything in our knapsack. Thus, we have no choice but to have a value and weight of 0. As such, if we know that our minimum value is at most 0 and our maximum weight is at least 0, then a valid list value for L' is just the empty list, so we can call our success continuation in sc []. Otherwise, we must call the failure continuation, as the problem is not solvable.
Note that, since we plan to write this function recursively, if we were given an initial list that was non-empty, we may eventually recurse down to the empty case. It may then seem like a concern that we are calling sc [], as we might actually call sc on a list that contains elements. Note that this is not a concern - by the structure of CPS functions, if we were to recurse down to the base case, our "promise" is that the success continuation sc that we enter the base case with is not the "original" sc that we were passed - by this point, it should have accumulated a great deal of "information" and thus become more advanced than simply returning sc [], for the original sc. For the base case, it is sufficient to simply solve it from the perspective of having been originally given [].
In the recursive case, we now have to think about how we might solve the knapsack problem given that we have a non-empty collection of items to take. Right off the bat, we can say that if our maxWeight < 0, then this problem is unsolvable, since we cannot possibly have a negative total weight (our weights in this problem are strictly positive), so in that case we would simply call our failure continuation.
Otherwise, however, we now need to actually think about what to do. Oftentimes, it is very helpful reduce the problem to making a binary choice, and then simply explore the consequences of doing so from there. In this case, we can imagine our choice to be whether to put the first element of the list into the knapsack, or to not.
| (v, w)::xs => if maxWeight < 0 then fc ()
else
knapsackCPS ((v, w)::xs) (minVal - v) (maxWeight - w)
(fn L' => sc ((v, w)::L')) (fn () => knapsackCPS xs minVal maxWeight sc fc)
What does our recursive call for putting the first element (v, w) into the knapsack look like? It takes the form of knapsackCPS ((v, w)::xs) (minVal - v) (maxWeight - w) sc' fc', for some sc' and fc' that we will determine later. We keep the list the same, to account for the fact that we can have duplicates - in the next step, we want to reconsider whether we want to put (v, w) on again. If we commit to putting (v, w) in the knapsack, however, we need to somehow encode the fact that our value has gone up by v, and our knapsack's weight has gone up by w. This is achieved by setting the new minimum value to be minVal - v, and the new max weight to be maxWeight - w - we simply lower our thresholds, which is functionally the same.
What should our continuations be? Remember that by the recursive leap of faith, we can assume a kind of "promise" of this recursive call - that is, we can assume that knapsackCPS ((v, w)::xs) (minVal - v) (maxWeight - w) sc' fc' obeys the same ENSURES clause as was written above, for its own sc' and fc'. We now should define what to do in the case that either is called.
We are, at this point, not actually at the stage where we know if sc' or fc' is going to be called, or on what, if at all. The power in CPS comes from the fact that this does not matter, and we can write our algorithm despite that. Earlier, we discussed the concept of continuations as contingency plans. In this function, we are going to be using that strategy to full effect.
Think of sc' and fc' as contingency plans for the success and failure case, respectively. If we were to succeed on this recursive call, what should we do? If we were to fail, what should we do? Even though we have no idea what the input to the continuation is, the fact that it is a function allows us (inside the scope of the body of sc') to assume we have access to it.
As such, the first thing we may write for sc' is fn L' => .... Now, we must fill in the ellipses. If sc' is called, we know that it must be called with an appropriate L' that satisfies the ENSURES conditions. Recall that this recursive call emerged in the first place from our choice - to place (v, w) inside of the knapsack. Thus, if the call to knapsackCPS succeeds, we know that placing (v, w) inside the knapsack must be feasible, by extension. So then we know it makes sense to write fn L' => sc ((v, w)::L') for sc', which intuitively means "take the answer (knapsack) to the recursive call and then put (v, w) in it, then call success on it". Thus, we have written down a contingency plan for what we should do if, at some point in the future, our success continuation is called.
What about fc'? What should we do if we fail? Well, if our recursive call to knapsackCPS does not succeed, that must mean that our choice to place (v, w) inside of the knapsack was wrong. In that case, we want to make the other choice - to not put (v, w) inside the knapsack. Thus, we write fn () => knapsackCPS xs minVal maxWeight sc fc, which has the exact same parameters as what we were initially passed, except we have gotten rid of (v, w) (since we know to put it in the knapsack is a mistake). Our sc and fc remain the same, since on a sucess or fail to this call, we just do whatever we would normally do on a success or fail.
This, in only a few lines (and generous whitespace), we have written an algorithm for a backtracking knapsack problem solver. While it looks intimidating at first, the overall algorithm reduces down to only a few simple steps, which is written in an elegant and explicit manner due to continuation passing style.
Conclusions
In this section, we explored the idea of continuation passing style, which lets us phrase the control flow of our functions in a more explicit manner, granting us more versatility in our implementation. We saw how CPS functions can be viewed as simply a more advanced form of accumulation, as well as how having multiple continuations (corresponding to success and failure cases) allows us to explore expansive trees of binary choices to find solutions. -->
- In fact, it is alpha equivalent!↩
- Though perhaps we should not be, until we write a full inductive proof of correctness!↩
- Otherwise, you should be quite concerned about the competency of the author, and you would probably be better off reading a different help site.↩